CNN的结构主要有三层组成: Convolutional Layer, Pooling Layer, and Fully-Connected Layer. 一般卷积层后面都会跟一个激活函数。 CNN就像是一个非线性函数,输入是raw pixel,输出可以是分类的score(对于分类的函数来说)。
Convolutional Layer
卷积层是CNN 的核心,也是计算量最大的部分。它有两个特点:Local Connectivity,Parameter Sharing.
Local Connectivity
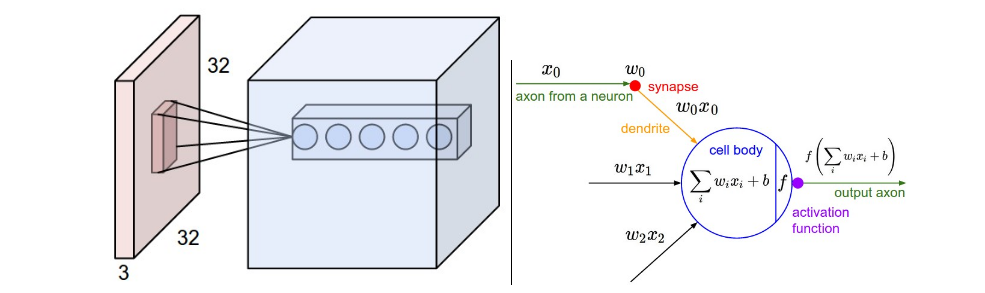 如图1所示,一个神经元连着一个小区域,这个区域的学术名称叫做receptive field(感受野)。感受野的大小与滤波器的大小一致,滤波器与感受野做卷积操作。相当于矩阵做点乘操作。图1中filter的大小可以是5x5x3,可以是3
x3x3,可以是7x7x3,唯独最后的3不能变,是因为图像的channel是3,维度要对应上,有的文章把这个3称作depth。
如图1所示,一个神经元连着一个小区域,这个区域的学术名称叫做receptive field(感受野)。感受野的大小与滤波器的大小一致,滤波器与感受野做卷积操作。相当于矩阵做点乘操作。图1中filter的大小可以是5x5x3,可以是3
x3x3,可以是7x7x3,唯独最后的3不能变,是因为图像的channel是3,维度要对应上,有的文章把这个3称作depth。
假设使用一个filter来对input进行卷积操作,输出大小是多少呢?这需要取决于四个超参数:
- filter数量K;
- filter的sizeF;
- filter移动步长S;
- zero-padding 的大小P;
假设输入,那么输出为
一般来说,filter的大小为3x3,5x5,都是奇数,也有1x1的,当步长S=1时,一般zero-padding的大小一般为(F-1)/2,这样做的原因是可以保持输出与输入的尺寸大小一致。
注意这里设置参数比较重要,如果设置的结果得到的或者不是整数,在caffe或者tensorflow这样的深度学习库会报错。必须设置的参数在计算后得到的结果可以整除。例如:,,,时,就会有错误,因为, 4.5不是整数。
Tip:AlexNet那篇文章里说图片size是224x224应该是错误的,应该是227x227,文章里并没有说明有padding,是悬案,cs231n老师如是说。
Parameter Sharing
所谓参数共享,即共用一个卷积核。以AlexNet为例,输入图片大小为227x227x3,第一个卷积层filter的大小为F=11,步长S=4,不使用zero-padding,filter个数为96,这样卷积操作之后得到的feature map大小为55x55x96。这个feature map就是我们所说的神经元组成,55x55x96个神经元,每个神经元与一个11x11x3的感受野相连接,那么参数的个数就是55x55x96x(11x11x3+1)=290400x364=105705600个参数,一层就这么多参数,是不可以接受的。
所以就提出一个合理的假设,如果这个filter在这个位置可用,那么在另外一个位置也应该是可用的。也就是说,每一层的feature map(96个feature map中的一个称为一层)所用的filter是一样的,这样就变成了卷积操作,这也是为什么称为卷积层的原因。这时候参数数量变为96x(11x11x3+1)=34848个,降低了好几个数量级。+1是偏置项参数。
Tip:反向传播的时候,同一层的神经元都会计算自己的梯度,但是梯度会累加在一起,然后更新滤波器参数的权重。(因为同一层神经元他们的滤波器参数是共享的)
Tip:cs231n笔记说有时候参数共享没有意义,因为期望就是在图片不同位置学到完全不同的特征,比如人脸,眼睛和鼻子特征不一样,这时候就不用参数共享,将这层称作局部连接层(Locally-Connected Layer).
Tip:cs231n笔记里有代码和动态图展示了卷积层是如何操作的。
补充:
- 1x1卷积:这里的1x1卷积不是传统意义上的1x1卷积,因为每一层的输出都有depth,比如输入层输出的图片是227x227x3,做1x1卷积,实际上我们的filter的size是1x1x3。
- 扩张卷积(Dilated convolutions):扩张卷积即卷积核中间有间隙。举例来说:在某个维度上滤波器w的尺寸是3,那么计算输入x的方式是:
w[0]*x[0] + w[1]*x[1] + w[2]*x[2],此时扩张为0。如果扩张为1,那么计算为:w[0]*x[0] + w[1]*x[2] + w[2]*x[4]。不太理解他的作用.
Pooling Layer
Pooling层的作用是降采样,缩小数据的尺寸。可以减少网络中的参数,计算资源耗费减小。最常见的使用2x2的核,不畅为2,这样就可以去掉75%的信息。pooling的方式有max pooling,average pooling,L2-norm pooling。实践证明,max pooling比average pooling好。
Tip:max pooling的数学就是就是max(x, y), 在反向传播的时候,梯度仅会沿着最大的数来回传,所以通常在前向传递的时候,记录最大元素的索引,反向传播经过pooling层的时候就会很高效。
Tip:有发现认为,在训练一个良好的生成模型时,弃用汇聚层也是很重要的。比如变化自编码器(VAEs:variational autoencoders)和生成性对抗网络(GANs:generative adversarial networks)。所以以后可能会弃用pooling层。
Fully-Connected Layer
全连接层就是之前说的神经网络。
将FC层转换为Conv层
首先说怎么转换,再说转换的好处。
怎么转换
卷积层(Conv层)和全连接层(FC层)的唯一区别就是conv层的神经元与输入数据的一个局部区域连接,并共享参数。但是神经元计算都是矩阵点乘,函数形式是一样的,这就为二者转换提供了基础: 假设一个fc层的神经元个数是4096,他的输入数据大小是7x7x512,那么参数的数量就是7x7x512x4096,那如果将该层转换为conv层,那么可以看成是一个卷积核大小为7,zero-padding为0,步长为1,卷积核个数为4096的conv层(卷积核尺寸与输入数据大小一致),此时由于conv层特有的参数共享,参数数量为7x7x4096。参数减少,计算量就会减小。
转换的好处
转换的好处一就是上面说的,减少了参数,第二个好处是translational invariance,可以参考reddit上的讨论,这个在后面的课程会讲,等我上完后面的课程来补。
CNN结构概述
一般的CNN结构如下:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
*代表重复几次这样的操作,POOL?代表pooling层可选,通常N<=3,0<=K<3
Tip:使用多个小的卷积核来代替一个大的卷积核。距离来说,对于一个输入为7x7大小的数据,如果直接使用7x7卷积核(一层卷积层)不如使用3x3卷积(三层卷积层)核效果好(VGGNet实验结果好像是证明了的).其次就是参数也更少,第一种有7x7=49个参数,第二种只有3x(3x3)=27个参数。后者可以表达出更多的特征,使用的参数更少,缺点就是反向传播的过程中,由于有三层卷积层,会占用更多的内存。
Tip:现在有google的Inception结构和MSRA的 Residual Net都采用了新的结构,跟上面提到的结构有所不同,效果更棒。
层的尺寸设置规律
输入层一般可以被2整除很多次,比如32,64,96,224,384,512.通常对于大小不一的图片,我们会将其resize为一个正方形图片。 卷积层一般使用3x3(步长为1),最多5x5(步长为2),对数据进行zero-padding,这样卷积层会保证输入层的数据大小与其输出大小一致。 Pooling层:一般使用max pooling, kernel size为2x2,步长为2.这样丢弃75%的信息。
目前知名的CNN结构
内存消耗
目前构建CNN的瓶颈是内存,最好的GPU,显存也就是12G。 需要注意三种内存占用来源:
- 中间数据:每一层都会产生激活值,需要存储,用来做反向传播;
- 参数:网络本身的参数,以及一些优化算法如momentum,RMSProp的缓存,通常参数的耗费内存是你理论计算值的三倍;
- 零散:成批的训练数据,扩充的数据。
内存不够,降低batch size的大小。