Improving the way neural networks learn
Cost function
quadratic cost function
如果使用 其中 这样的cost function,根据链式法则,对weight和bias的导数为 从上面的公式可以看出,在做反向传播的时候,用来更新参数的梯度,和成线性关系。越小,那么更新参数的幅度就会很小,那么可能就出出现loss下降的慢,收敛速度慢的情况。就是sigmoid函数,如下图所示:
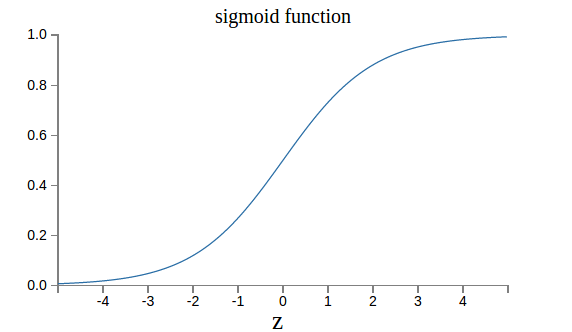
从图中可以看出,当sigmoid函数的输入大于3, 那么输出接近为1,此时的导数很小(输入很小时,输出接近为0,导数一样很小),而实际训练过程中,出现输入远大于3的可能性也很大,那么这时候导数很小,根据上面所述,梯度与sigmoid的导数成线性关系,就会导致收敛速度慢的情况。该网址有动图展示。
cross-entropy cost function
如果使用 我们对weight和bias求导,可得 其中 此时可以看出使用cross-entropy cost function 的好处是,在求导的时候,与无关了,当你的输出与我们的真实label 相差的越远,梯度越大,这正是我们所期望的,从而达到快速收敛的效果。该网址有动图展示。
思考:是不是因为sigmoid函数在输出接近为1的时候,导数小,影响收敛速度,所以后面人们设计出新的激活函数ReLU呢?毕竟ReLu在时,是一条直线。
The quantity is sometimes known as the binary entropy.
注意:以上讨论quadratic cost function收敛慢,是在输出层加了sigmoid的情况下,如果输出层不加sigmoid,即,此时残差就会变为.此时再看weight和bias的偏导:
我们会发现,之前导致收敛速度慢的项已经消失,所以如果输出层不加sigmoid,使用quadratic cost没有问题。
注意:神经元输出接近为1,我们成为神经元饱和(neurons saturate)现象.
softmax loss
这里输出层应用softmax function, 即输出层第j个神经元的输出为 其中。 这么做的有点是,确保输出层所有输出之和为1,那么我们就可以解释为每个输出代表的是概率。 以MNIST为例,输出层有10个神经元,每个神经元代表的是每种结果的可能性,做预测的时候,自然选择概率最大的那个神经元作为预测结果。
实际在算loss的时候,会对softmax 函数取对数,即. 这么做的好处?以MNIST数据举例来说,假设输入为7,我们网络输出接近为1时,此时对应的loss就很小,相反,如果此时接近为很小,那么此时的loss就会很大。这正是我们所期望的。
softmax loss如何解决学习慢的问题?softmax loss会不会有和quadratic cost一样的问题呢?答案是不会有,他对weight和bias的偏导如下: 与无关,和cross-entropy的偏导很相似,即使神经元饱和,也能快速收敛(这句话我不知道说的对不对,但是仅从目前已知条件来看,是没错的,以后等待考量) 注意: 在输出层应用sigmoid的cross-entropy loss和 在输出层应用sofxmax function的softmax loss,在更新参数的偏导公式是一样的。