目前激活函数有以下几种:
Sigmoid
优点如下: 很容易解释神经元的"firing rate",我搜了一下,"firing rate"是神经编码里的名词,具体没有太关注。 缺点如下:
- 容易饱和,导致梯度为0;
- 非zero-centered,即sigmoid的输出的均值为0;
- 操作比较费时,但是相较于卷积这些操作,不足以提之。
注意:非zero-centered指的是sigmoid的输出恒为正,在多层神经网中,sigmoid的输出作为下一级的输入,在反向传播更新参数W的时候,会导致每次更新参数要么全部加,要么全部减,取决与输入。推理如下: 可以看出,由于总是大于0(此处为这一层的输入,也就是上一层sigmoid的输出)。梯度总是和同号,即要么全为正,要么全为负。这样就会导致zig zag path,至于为什么这么描述,我其实不太理解,不过正常更新参数迭代的时候,在每一轮迭代的过程中,参数中有的增大有的减小,这样可以快速收敛,而不是同时增大或同时减小,这会导致收敛很慢。参考
tanh
缺点:依然容易饱和,导致梯度消失。 不过相对sigmoid来说,解决了zero-centered的问题。
ReLU
优点:
- 不会饱和;
- 计算很快;
- 收敛快(sigmoid/tanh的6倍) 缺点:
- 非zero-centered的输出;
- 当输入为小于0的时候,ReLU输出为0,这就很有可能导致该参数一直无法更新.
注意:由于小于0,被抑制,所以在使用ReLU的时候,通常给bias初始化为0.01。例如,将学习率设为较大的时候,可以发现40%的W一直被抑制。当然一般开始的学习率都会设置的比较合理,不会过大。
Leaky ReLU
优点:
- 不会饱和;
- 计算快;
- 收敛快(sigmoid/tanh的6倍)
- 不会出现ReLU在小于0的时候,就出现抑制的情况。
注意:还有一种PReLU激活函数:, 作为一个参数放在网络里学习。
Maxout
优点如下:
- ReLU和Leaky ReLU形式的扩展,他们的优点他都有;
- 不会出现抑制的情况; 缺点:
- 激活函数的参数等变多。
ELU
优点如下:
- ReLU有的优点他都有;
- 不会被抑制;
- 输出的结果接近Zero mean. 缺点:
- 操作耗时。
激活函数图如下图所示:
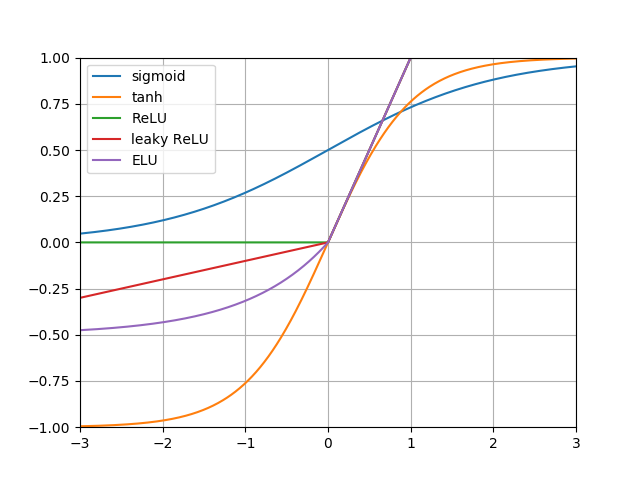
小结
在实际实验中:
- 使用ReLU;
- 可以尝试Leaky ReLU/maxout/ELU
- 不要使用Sigmoid和tanh