L2 Regularization
在目标函数加入,这样在更新参数时,要在原本更新梯度的后面加入正则w += -lamda * W。L2正则项会将所有参数拉伸,使网络更倾向使用全部特征,而不是依赖小部分特征。
对于一组特征x=[1,1,1,1],他的label是1,不加正则项,训练之后可能会得到W=[1,0,0,0],但是加入正则后,训练之后的结果可能会偏向W=[0.25, 0.25, 0.25, 0.25],这就是拉伸所有参数,倾向使用全部特征的含义。
L1 Regularization
在目标函数加入,L1正则化倾向使参数变的稀疏,即W中很多为0.一般情况下,L2比L1好点。如果已知数据十分稀疏,那么L1效果自然更好。
还有一种正则化方式,将L1和L2想结合, ,也被称作Elastic net regularizaton.
Max norm constraints
一种形式的正则化是给每个神经元中权重向量的量级设定上限,并使用投影梯度下降来确保这一约束。在实践中,与之对应的是参数更新方式不变,然后要求神经元中的权重向量必须满足这一条件,一般值为3或者4。有研究者发文称在使用这种正则化方法时效果更好。这种正则化还有一个良好的性质,即使在学习率设置过高的时候,网络中也不会出现数值“爆炸”,这是因为它的参数更新始终是被限制着的。
Dropout
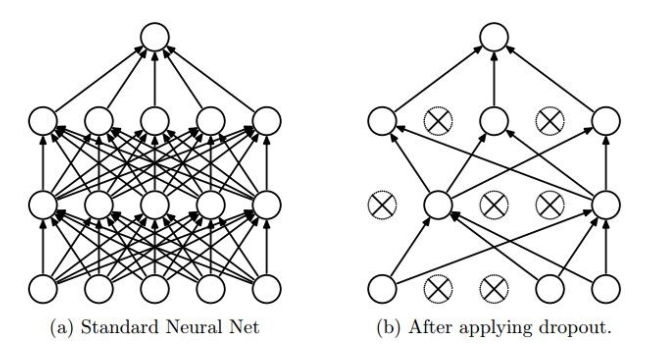
由Srivastava提出,论文见Dropout: A Simple Way to Prevent Neural Networks from Overfitting.思想是在前向传播的时候,随机使一些神经元失活,每次数据都是更新不同子网络的参数(子网络并不是独立的,而是共享参数);在测试的时候,使用完整的网络。可以理解为model ensemble,即训练了多个不同的网络,然后在测试的时候将预测结果平均,得到较好的performance。
一个3层神经网络的普通版随机失活可以用下面代码实现:
""" Vanilla Dropout: Not recommended implementation (see notes below) """
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
""" X中是输入数据 """
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # 第一个随机失活mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # 第二个随机失活mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # 注意:激活数据要乘以p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # 注意:激活数据要乘以p
out = np.dot(W3, H2) + b3
在上面的代码中,在训练阶段随机使神经元失活,然后在预测阶段将不用随机失火,但是要对结果做一个平均,乘以p就是做平均。通过超参数p来控制失火神经元数量。为什么乘以p就是做了一个平均呢?

如图2所示,predict阶段是用训练时期的所有子网络,然后平均他们的预测结果。注意,虽然这里设为p=0.5,并不是每次都是使一半神经元失活,可能第一次使所有神经元失活,但是第二次使所有神经元都激活,但是随着次数的增加,最后平均下来,就是每次失活一半神经元,这样按照图2的推导过程,就可以得出乘以p就是平均所有子网络的输出的结果。
官方文档给出的解释更加有理有据:假如,那么在训练的时候该神经元输出的期望就是,神经元有的概率被抑制,输出为0,那么在预测阶段所有的神经元都是激活的,为了保持和训练阶段相同的预期输出,所以需要调整.
那每次都在predict阶段做rescale,有的人看着不爽,可以将他移到训练阶段。在训练的时候,就把输出调为正常的输出。如下:
"""
反向随机失活: 推荐实现方式.
在训练的时候drop和调整数值范围,测试时不做任何事.
"""
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # 第一个随机失活mask. 注意/p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # 第二个随机失活mask. 注意/p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用数值范围调整了
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
这就相当于我每次用一半神经元来训练,得到的结果也是全部神经元预测结果除以2的,那么我直接在用一半神经元的时候把结果扩大2倍。那么在predict的时候,embedding所有的子网络,就不用在除了,因为我们之前已经乘过了。
Dropout的效果很好,有效的避免过拟合,推荐使用。